作者:Will Fu-Hinthorn
在本篇博文中,我们将探讨几种常见的多智能体架构。我们将讨论不同架构的动机和限制。我们将在 Tau-bench 数据集的变体上对其性能进行基准测试。最后,我们将讨论我们对 “supervisor”实现 所做的改进,这些改进在该基准测试上使性能提高了近 50%。
多智能体系统的驱动因素
几个月前,我们 对单个智能体架构 随着工具数量和上下文大小增加时的扩展性进行了基准测试。我们发现,即使上下文与目标任务无关,随着上下文大小的增加,性能也会显著下降。扩展系统以处理更多工具和上下文是多智能体系统的一个常见动机。
多智能体系统的另一个驱动因素是遵循工程最佳实践。我们接触的许多团队更喜欢设计独立的智能体,因为它们更具模块化,更容易更新、评估、维护和并行化。
多智能体系统的最后一个驱动因素是,许多智能体将由不同的开发者和团队开发。在这种情况下,朴素的单智能体架构可能不可行。如果每个智能体都能贡献独特的东西,一个有效的多智能体系统可以比任何单个智能体孤立地实现更多。
鉴于这些原因,我们认为多智能体架构将变得更加普遍。
通用架构与定制架构
如今,大多数构建多智能体架构的团队都是为垂直特定应用而构建的。我们今天看到的大多数多智能体架构本质上都相当定制化。这是因为定制认知架构——经过仔细思考——比通用架构在该特定领域能产生更好的结果。
尽管如此,通用多智能体架构出于几个原因也很有趣。
易于上手。 通用多智能体架构可以更容易地开始使用多智能体系统。一个简单的智能体架构,其中所有通信都通过“工具调用”完成,通常不如特定于应用程序的工作流高效,但它更容易作为起点使用。
“自带智能体”。 如果您正在构建一个通用智能体,您可能希望其他人“自带智能体”。连接到这些智能体需要一个相当通用的架构。我们已经看到这种模式通过 MCP(“自带工具”)连接到标准 API 中发生。客户端(Claude、Cursor 等)使用 MCP 工具的方式是通用的。我们设想类似的事情也会发生在智能体身上。
那么,最好的通用多智能体架构是什么?
数据
我们在一份由 Yao 等人提出的 **τ-bench** 的修改版本上进行了实验(链接)。τ-bench 旨在测试不同的单智能体认知架构/提示策略在现实场景(如零售客户支持、机票预订等)中的表现。我们修改后的数据集版本和实验代码可以在 multi-agent bench 仓库中找到。
为了更有效地测试多智能体系统在处理更复杂领域时的扩展性,我们在数据集中增加了 6 个额外的环境:家居装修、技术支持、药房、汽车、餐厅和 Spotify 歌单管理。每个环境都有 19 个不同的工具来促进对相应领域的交互,以及一个包含相关领域说明的“维基”。这些合成领域中没有一个对于完成原始数据集中的任何任务是必需的(或有用的)。这些环境纯粹被设计为逼真的“干扰项”,测试每个智能体设置在提供其他(不相关的)工具和指令集“以防万一”的情况下能够执行得有多好。
我们对 **τ-bench** 零售领域测试集的前 100 个示例进行了实验,向智能体提供越来越多的干扰环境,以展示每个系统如何平衡额外的上下文。这测试了常见智能体系统如何扩展的“最佳情况性能”。我们称之为“最佳情况”,因为辅助领域不需要成功完成每个任务。在实践中,除了过滤掉系统理论上可以采取的总行动集中无关的工具和指令外,通过测试用例所需的协调很少。
实验
我们对三种不同的架构进行了实验。所有这些实验都使用了 `gpt-4o` 作为模型。
注意:根据您的应用程序的限制,其中一些架构可能不可行。我们始终建议从您的目标(成功的定义)和限制开始选择设计模式。
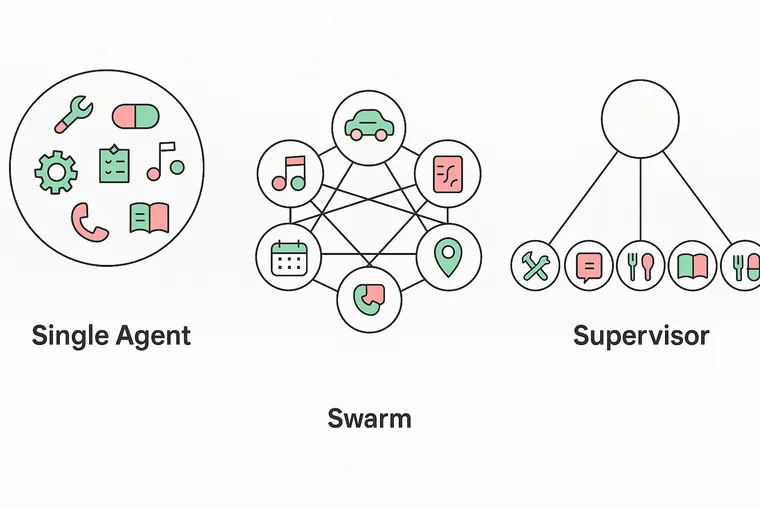
单智能体
这是一个具有单个提示且可以访问所有领域工具和指令的工具调用智能体。这是我们想要改进的基准。
在实现方面,我们使用了 LangGraph 的 `create_react_agent` 实现。
注意:此架构并非在所有情况下都可行。例如,如果您希望其中一个子领域由第三方智能体处理,那么您按定义就不能使用单个智能体。
Swarm (群)
在这种架构中,每个子智能体都能感知并可以向群组(或 swarm)中的任何其他智能体进行交接。如果一个智能体响应,该响应将直接发送给用户。当一个智能体处于活动状态时,它将一直处于活动状态,直到它交接给另一个智能体。同一时间只有一个智能体可以处于活动状态。
在实现方面,我们使用了 LangGraph 的 `langgraph-swarm` 包。
注意:此架构并非在所有情况下都可行。这要求每个子智能体都知道架构中的所有其他智能体。如果您正在与第三方智能体合作,情况很可能不是这样。您也不希望第三方智能体在与用户交互时保持“活动”状态。
Supervisor (监督者)
在这种架构中,一个单一的“监督者”智能体接收用户输入并将工作委托给子智能体。当子智能体响应时,控制权会交还给监督者智能体。只有监督者智能体才能响应用户。
在实现方面,我们使用了 LangGraph 的 `langgraph-supervisor` 包。
注意:此架构对子智能体做出的假设非常少,因此应适用于所有多智能体场景。
结果与分析
我们在两个维度上展示结果
- 得分:由 Tau Bench 使用的 XYZ 测量
- 成本(Token):每次实验使用的 Token 数量
得分

我们看到,当存在两个或更多干扰域时,单智能体基线性能急剧下降。当只有一个干扰域时,单智能体的性能略好。
我们看到,Swarm 架构在各方面略优于 Supervisor 架构。查看数据,性能下降是由于 Supervisor 正在进行的“翻译”。这是因为在 Supervisor 架构中,子智能体不能直接响应用户,而在 Swarm 架构中,它们可以。如果您玩过“传话筒”游戏,您应该很熟悉这个问题!
成本(Token)

我们看到,随着干扰域数量的增加,单智能体使用的 Token 持续增加,而 Supervisor 和 Swarm 则保持平稳。
我们可以看到,Supervisor 消耗的 Token 始终比 Swarm 多。这再次归因于 Supervisor 进行的“翻译”。这是因为在 Supervisor 架构中,子智能体不能直接响应用户,而在 Swarm 架构中,它们可以。
Supervisor 的改进
当我们最初测试 Supervisor 方法时,它的表现相当糟糕。直到进行了一些更改后,它的表现才开始变好。
这是一张包含旧 Supervisor 实现的图表

Supervisor 架构的大部分性能问题来自监督者智能体在子智能体和用户之间进行“传话”时的“翻译”。我们为缩小差距所做的许多更改都是为了消除“传话”游戏的影响。
注意:所有这些更改都作为选项包含在最新版本的 `langgraph_supervisor` 中。
移除交接消息
从子智能体的状态中移除交接消息,这样分配到的智能体就不必查看监督者的路由逻辑。这可以减少子智能体上下文窗口的混乱,使其更好地执行任务。即使是最新模型,上下文的混乱也可能对智能体的可靠性产生不成比例的影响。
转发消息
让监督者访问 `forward_message` 工具。该工具允许它直接将子智能体的响应“转发”给用户,而无需重新生成全部内容。这减少了监督者智能体错误释义子智能体响应所导致的错误。
工具命名
测试监督者智能体调用以交接给子智能体的工具名称的不同表述(“delegate_to_<agent>” vs “transfer_to_<agent>”)。
未来工作
我们还有一些下一步计划希望进行探索。
多跳代理
目前,所有问题只需要一个子智能体来响应。我们希望探索需要多个子智能体的问题的性能。
匹配单智能体性能
为什么当只有一个干扰域时,Swarm 和 Supervisor 的表现不如单智能体?大多数主要错误是由于“翻译”错误和附加上下文(来自交接)导致的性能下降。我们设法在一定程度上减少了这些问题,但性能仍然落后于单智能体。有什么方法可以提高性能到那个水平?
跳过“翻译”层
Supervisor 的大多数错误是由于“翻译”层造成的,在这种层中,只有 Supervisor 智能体被允许响应用户。是否有办法更有效地绕过这个翻译层,同时仍然正确地委托工作并确保响应时考虑到完整的任务上下文?
其他架构
是否存在可能产生更好结果的其他架构?这与“智能体即工具”相比如何?
结论
我们认为多智能体系统将变得更加普遍。虽然当今大多数成功的多智能体系统都具有相对定制化的架构,但我们认为随着模型的改进,通用架构将变得足够可靠,以至于其易于开发的优势会抵消其性能上的劣势。 `supervisor` 架构是最通用的(因为它对底层智能体做出的假设最少),但 Supervisor 架构的朴素实现可能会产生更差的结果。通过改进子智能体和用户之间的信息传递方式(以及上下文管理方式),可以帮助系统在保持跨多个域扩展能力的同时提高性能。您可以在 `langgraph-supervisor` 中使用我们提供的这些改进,并使用 LangSmith 等工具在您自己的数据上评估您的系统。
如果您想轻松尝试 Supervisor 架构(包括我们在此研究中取得的所有改进),您可以使用 `langgraph-supervisor` 轻松实现。