
编者按:我们很高兴分享这篇博文,因为它涵盖了我们在过去一个月中推出的几项高级检索策略,特别是其中许多策略依赖于更改摄取步骤。许多这些高级检索策略可以总结为更改文档索引的方式,以保留层次结构的概念。Neo4j 是用于这些任务的激动人心的数据库,因为它可以在图的一部分中表示这些层次结构。这还允许您轻松切换索引策略。
Tomaz 实现了一个包含四种不同 RAG 策略的 LangChain 模板。在此处查看:
检索增强生成应用程序似乎是 AI 应用程序的“Hello World”。如今,借助 LangChain 等 LLM 框架库,您可以在短短几分钟内实现“与 PDF 聊天”应用程序。
“与 PDF 聊天”应用程序通常依赖于向量相似性搜索来检索相关信息,然后将这些信息馈送给 LLM,以生成最终答案并返回给用户。
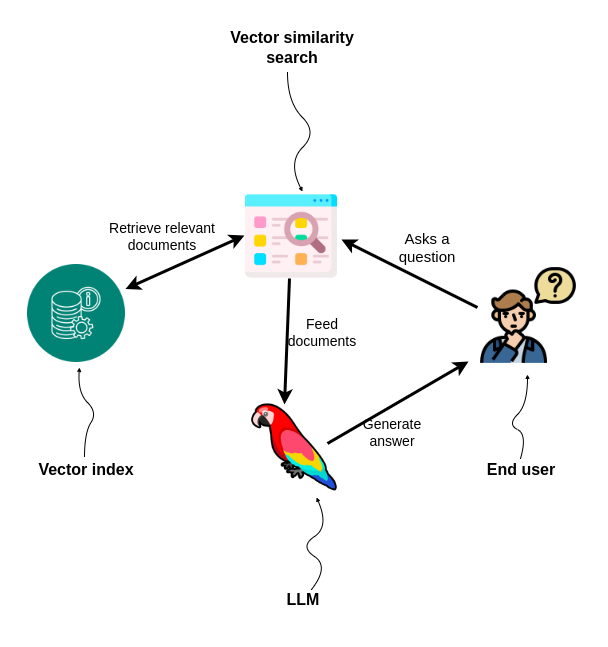
最近,越来越明显的是,简单的向量相似性搜索可能不足以满足所有用例。例如,我们看到了 step-back 提示方法 的引入,该方法强调了从任务的直接细节中抽离出来,关注更高级别的抽象的重要性。
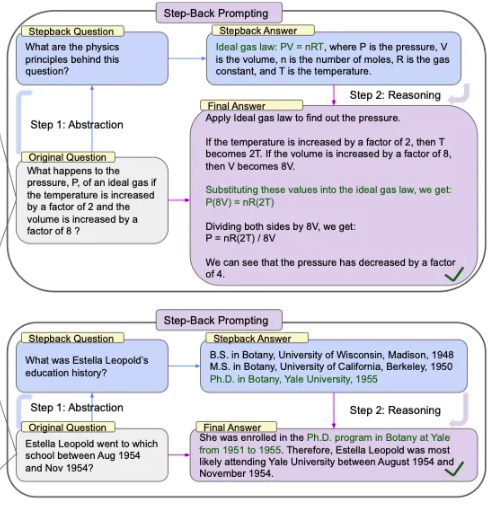
step-back 提示技术基于这样一个观察:直接处理复杂的任务可能会导致错误,尤其是在需要考虑大量细节的情况下。模型不会直接陷入复杂性,而是首先提示自己提出一个更通用的问题,该问题概括了原始查询的核心。通过关注这个更广泛的概念或原则,它可以检索到更相关和更全面的事实。一旦掌握了这些基础知识,模型就可以继续推理并推导出当前任务的答案。
另一方面,我们也看到了所谓的父文档检索器的引入,其假说可能是直接使用文档的向量效率不高。
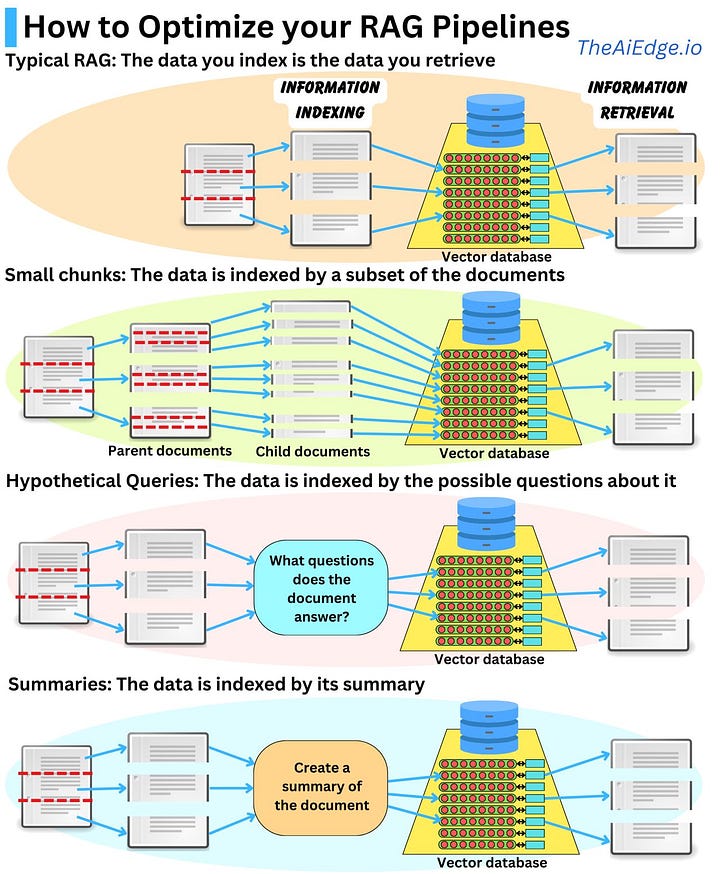
大型文档可以被分割成更小的块,其中更小的块被转换为向量,从而改进了相似性搜索的索引。虽然这些较小的向量能更好地表示特定概念,但仍会检索原始的大型文档,因为它能为回答问题提供更好的上下文。类似地,您可以使用 LLM 来生成文档所回答的问题。然后,文档将通过这些问题嵌入进行索引,从而提供与用户问题的更近的相似性。在这两个示例中,都会检索完整的父文档以提供完整的上下文,因此得名“父文档检索器”。
在这篇博文中,您将学习如何使用 neo4j-advanced-rag 模板 并使用 LangServe 进行托管。
Neo4j 环境设置
您需要设置 Neo4j 5.11 或更高版本才能按照本博文中的示例进行操作。最简单的方法是在 Neo4j Aura 上启动免费实例,它提供 Neo4j 数据库的云实例。或者,您也可以通过下载 Neo4j Desktop 应用程序并创建本地数据库实例来设置本地 Neo4j 数据库实例。
from langchain.graphs import Neo4jGraph
url = "neo4j+s://databases.neo4j.io"
username ="neo4j"
password = ""
graph = Neo4jGraph(
url=url,
username=username,
password=password
)Neo4j 高级 RAG 模板
LangChain Templates 提供了一系列易于部署的参考架构,任何人都可以使用。这是一种创建、共享、维护、下载和自定义链和代理的新方法。它们都采用标准格式,可以轻松地与 LangServe 部署,让您轻松免费获得生产就绪的 API 和一个游乐场。
neo4j-advanced-rag 模板通过实现高级检索策略,让您可以平衡精确的嵌入和上下文保留。
可用策略
1. 典型 RAG
- 传统方法,其中索引的数据与检索的数据完全相同。
2. 父检索器
- 数据被分成更小的块,称为父文档和子文档,而不是索引整个文档。
- 对子文档进行索引以更好地表示特定概念,同时检索父文档以确保上下文保留。
3. 假设性问题
- 处理文档以生成它们可能回答的潜在问题。
- 然后对这些问题进行索引以更好地表示特定概念,同时检索父文档以确保上下文保留。
4. 摘要
- 创建并索引文档的摘要,而不是索引整个文档。
- 同样,在 RAG 应用程序中检索父文档。
要使用 LangChain 模板,您应该首先安装 LangChain CLI
pip install -U "langchain-cli[serve]"然后,通过执行以下代码行即可检索 LangChain 模板
langchain app new my-app --package neo4j-advanced-rag此代码将创建一个名为 my-app 的新文件夹,并将所有相关代码存储在其中。可以将其视为 LangChain 模板的“git clone”等效项。这将在您的文件系统中构建以下结构。
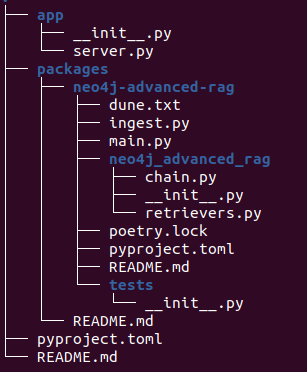
创建了两个顶级文件夹
- App:存储 FastAPI 服务器代码
- Packages:存储您为该应用程序选择的所有模板。请记住,您可以在一个应用程序中使用多个模板。
每个模板都是一个独立的项目,拥有自己的 poetry 文件、readme,可能还有一个 ingest 脚本,您可以使用它来填充数据库。在 neo4j-advanced-rag 模板中,ingest 脚本将根据 Dune 维基百科页面的信息构建一个小型图。运行之前,您需要确保添加相关的环境变量。
export OPENAI_API_KEY=sk-..
export NEO4J_USERNAME=neo4j
export NEO4J_PASSWORD=password
export NEO4J_URI=bolt://:7687请务必将环境变量更改为适当的值。然后,您可以使用以下命令运行 ingest 脚本。
python ingest.py摄取可能需要一分钟,因为我们使用 LLM 来生成假设性问题和摘要。如果您在 Neo4j Browser 中检查生成的图,您应该会看到类似的视图。
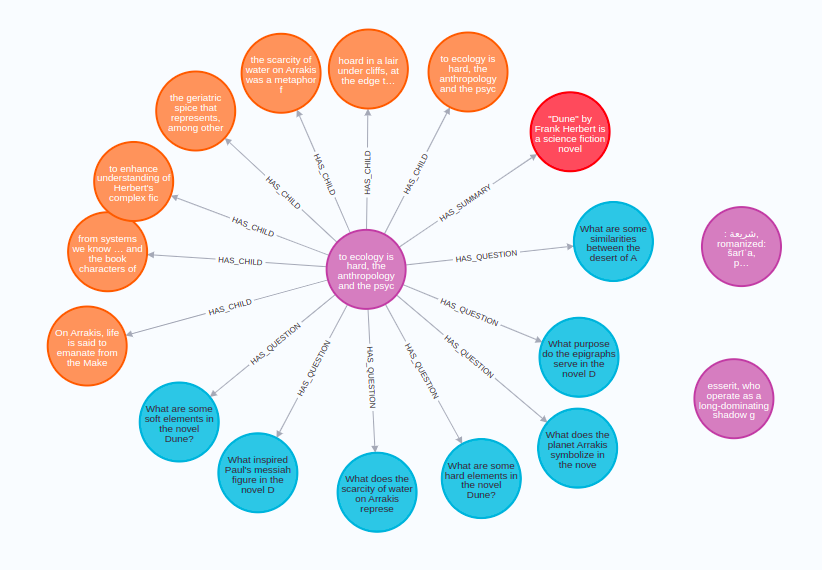
紫色节点是父文档,长度为 512 个 token。每个父文档有多个子节点(橙色),其中包含父文档的一个子集。此外,父节点还包含以蓝色节点表示的潜在问题和一个以红色表示的单个摘要节点。由于我们在单个存储中有所有不同策略所需的数据,因此我们可以轻松地在 Playground 应用程序中比较使用不同高级检索策略的结果。您需要做的一件事是将 server.py 更改为包含 neo4j-advanced-rag 模板作为端点。
from fastapi import FastAPI
from langserve import add_routes
from neo4j_advanced_rag import chain as neo4j_advanced_chain
app = FastAPI()
# Add this
add_routes(app, neo4j_advanced_chain, path="/neo4j-advanced-rag")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)现在,您可以通过在根应用程序目录中执行以下代码行来服务此模板。
langchain serve最后,您可以在浏览器中 打开 playground 应用程序,并比较不同的高级 RAG 检索方法。
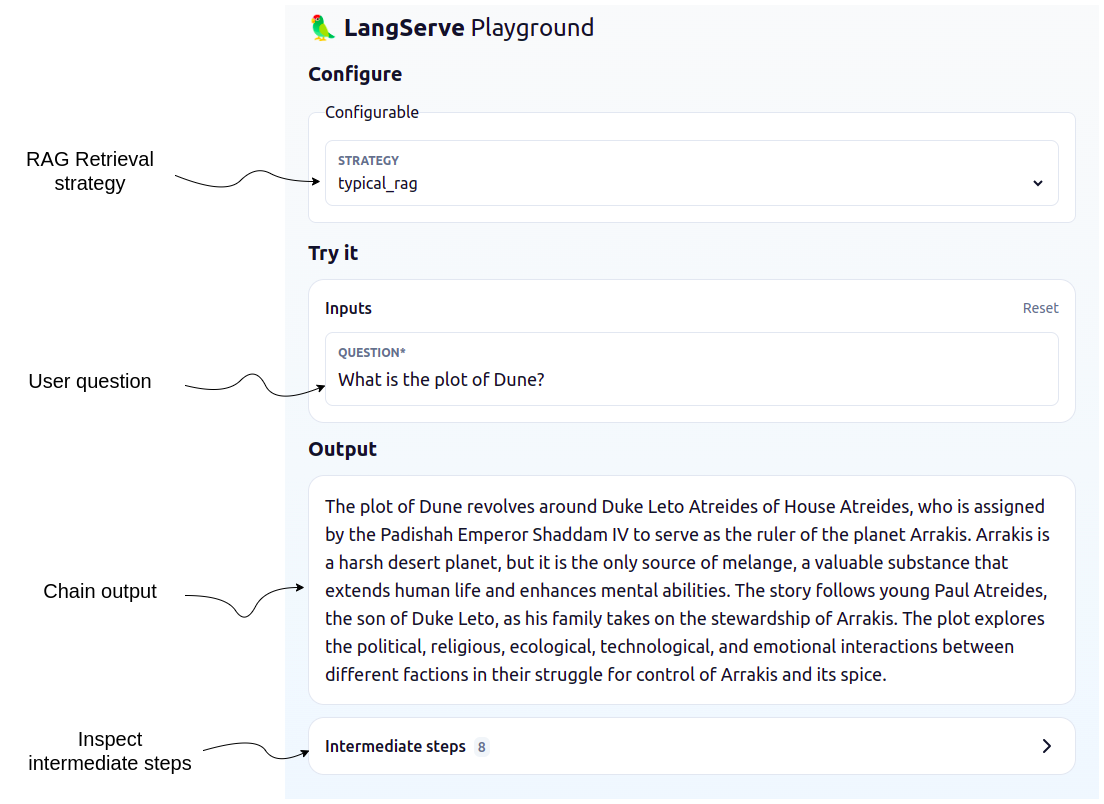
playground 非常好,因为它提供了一个漂亮的用户界面来测试和检查各种 LangChain 模板。例如,您可以展开“中间步骤”,并检查传递给 LLM 的文档、提示中的内容以及链的所有其他详细信息。
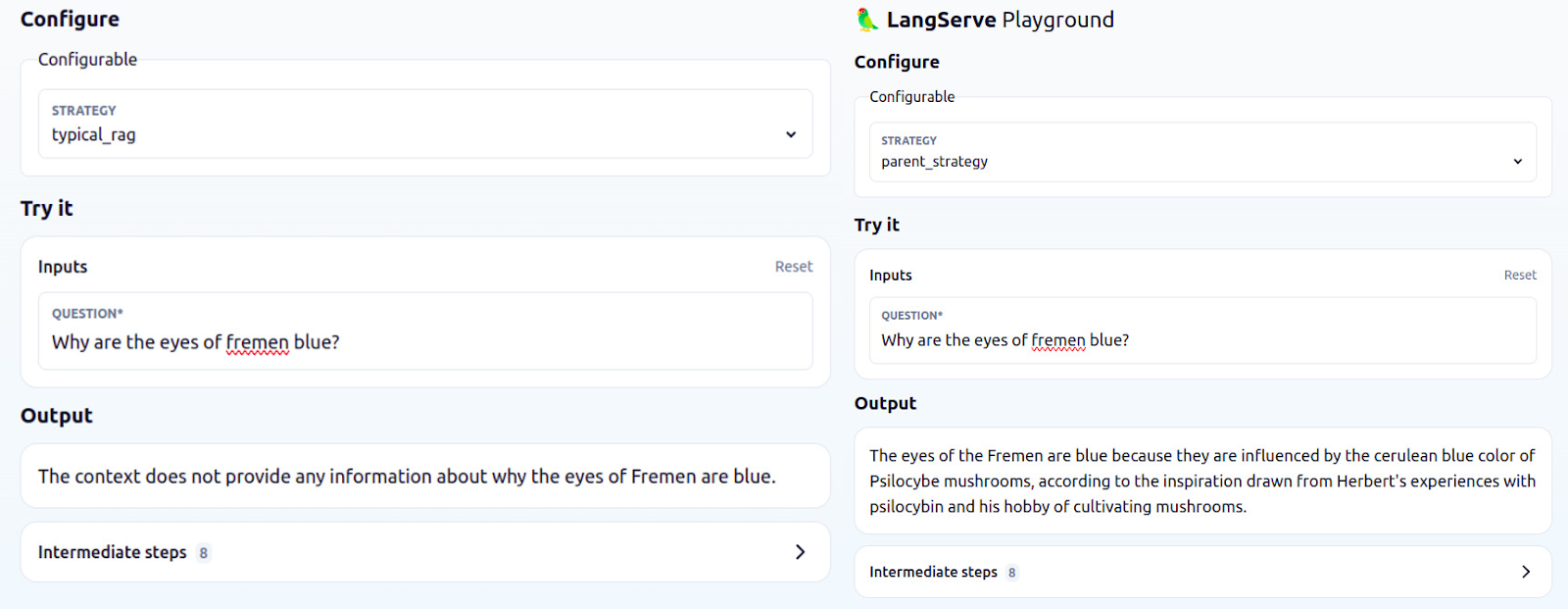
由于策略可以在下拉菜单中选择,因此您可以轻松地比较输出如何根据所选的检索策略而变化(或检查“中间步骤”部分中的文档)。
总结
在当今的 RAG 应用程序中,从大型文本语料库中检索准确且有上下文的信息至关重要。传统的向量相似性搜索方法虽然强大,但在嵌入较长文本时有时可能会忽略特定上下文。通过将较长文档分割成较小的向量并对这些向量进行索引以进行相似性搜索,我们可以提高检索准确性,同时保留父文档的上下文信息,以便使用 LLM 生成答案。类似地,我们可以使用 LLM 生成假设性问题或文本摘要并对其进行索引,但仍然返回父文档的文本。
尝试一下,让我们知道结果如何!